Chapter3(番外) s3のバケットでHTMLとCSSファイルの公開
今回は、Chapter3で用いたCLIとバケットを用いて、HTMLファイル及びCSSファイルを公開した。
HTML、CSSファイルの準備
まずは、HTMLファイルとCSSファイルを準備する。今回は、以下のHTML、CSSファイルを用いる。
HTMLファイル
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<title>タイトル</title>
<meta name="viewport" content="width=device-width">
<link rel="stylesheet" href="style.css">
</head>
<body>
<div class="boxA">
<div class="header1">
header(left)
</div>
<div class="header2">
header(right)
</div>
</div>
<div class="boxB">
<div class="box1">
<div class="box1-1">
menuber1
</div>
<div class="box1-2">
menuber
</div>
<div class="box1-1">
menube2
</div>
</div>
<div class="box2">
<div class="box2-1">
title
</div>
<div class="box2-2">
Hello World!
<br>I love Iketani Ran.
</div>
</div>
</div>
</body>
</html>
CSSファイル
.boxA::after {
content: "";
display: block;
clear: both;
}
.boxB::after {
content: "";
display: block;
clear: both;
}
.header1 {float: left;
width: auto}
.header2 {float: right;
width: auto}
.boxA {padding-top: 10px;
padding-bottom: 10px;
padding-left: 15px;
padding-right: 15px;
font-size: 40px;
font-weight: bold;
color:#ff9100;
background-color: rgb(255, 217, 0);
}
.boxB {
padding-top:20px;
}
.box1 {
float: left;
border:soild;
width: 200px;
border: 4px solid;
border-color:#a5a5a5;
padding-right: 5px;
padding-bottom: 100%;
}
.box1-1 {
padding-top: 5px;
padding-bottom: 5px;
padding-left: 5px;
padding-right: 100%;
font-size: 30px;
font-weight: bold;
color:#ff9100;
background-color: rgb(255, 217, 0);
}
.box1-2 {
padding-top: 5px;
padding-bottom: 5px;
padding-left: 5px;
}
.box2 {float: left;
width: 83%;
padding-left: 20px;
}
.box2-1 {padding-top: 5px;
padding-bottom: 5px;
padding-left: 5px;
padding-right:100%;
background-color: rgb(255, 217, 0);
color:#ff9100;
font-size: 30px;
font-weight: bold;
}
.box2-2 {padding-top: 5px;
padding-bottom: 5px;
padding-left: 5px;}
これをブラウザで表示すると、このように表示される。これを、バケットで表示する。
バケットの作成
次は、Chapter3と同じ方法でバケットを作成する。今回は、ir604というバケットを用意した。
そして、念のためバケット一覧を確認し、ir604バケットがあることを確認した。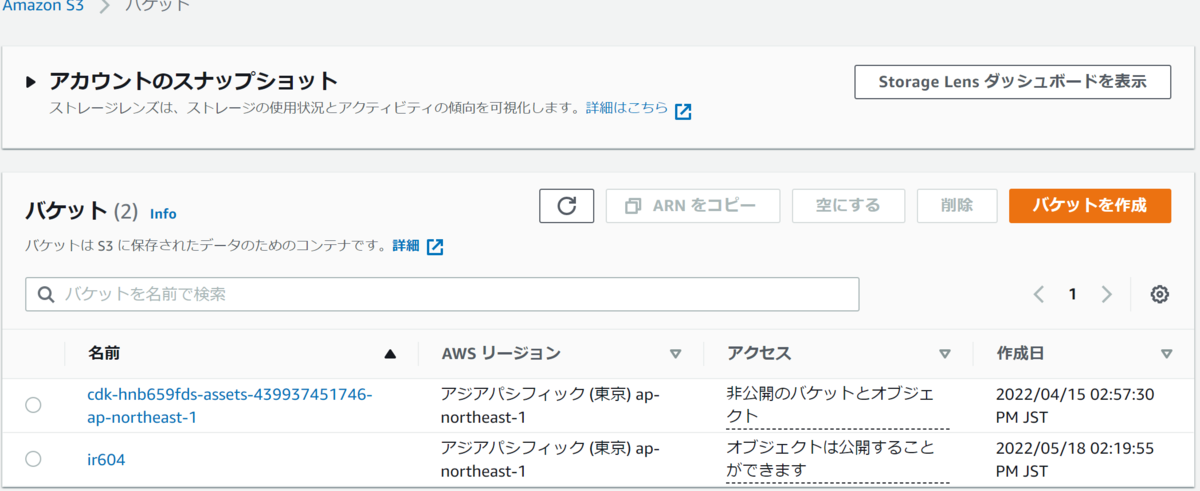
HTML、CSSファイルのアップロード
準備は整ったため、早速アップロードを行う。まず、htmlファイルとcssファイルが存在する箇所まで移動。
その後、両方のファイルを同じバケットにアップロードした。これも、Chapter3でやったことと同じ方法で行う。
これでアップロードされたはずなので、早速バケットを覗いてみる。 htmlファイルとcssファイルがアップロードされていることが確認できた。
htmlファイルとcssファイルがアップロードされていることが確認できた。
ついでにUbuntuの方でも確認してみた。こちらもChapter3と同じ方法で確認することが可能である。
HTMLファイルの表示
これで、アップロードも終わったため、早速、オブジェクトURLにアクセスし、ファイルを表示してみる。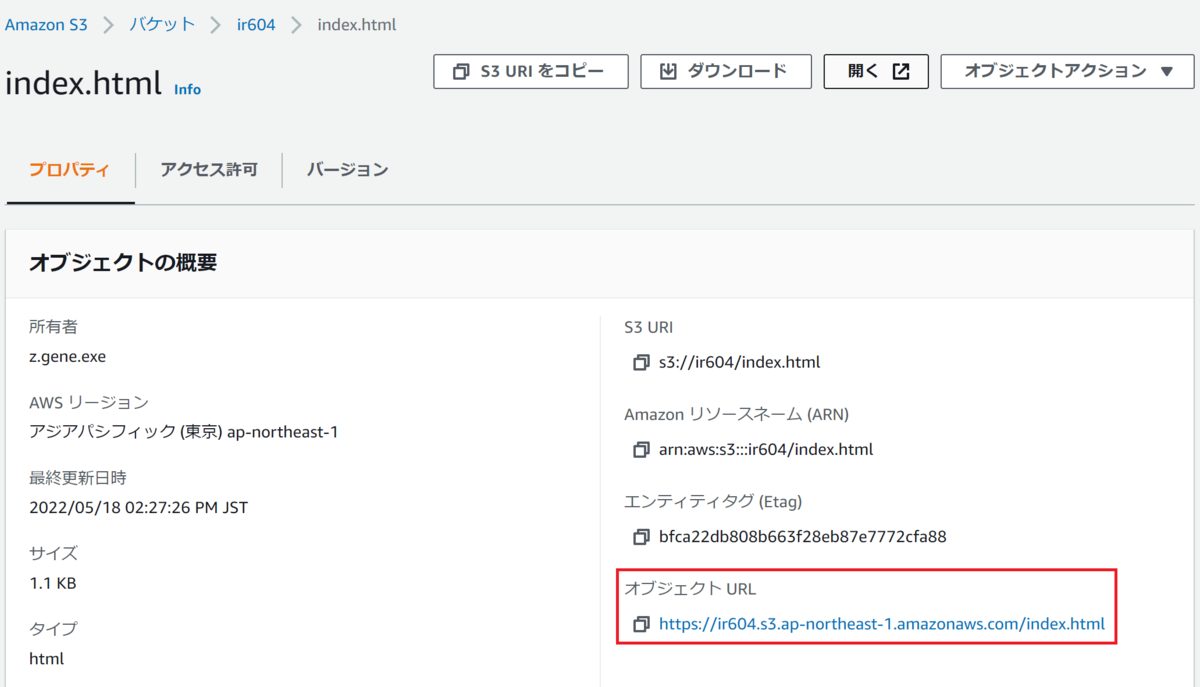
すると、このような表示がされた。
どうやら、アクセス許可をどうにかする必要があるとのことなので、バケット詳細ページまで戻り、アクセス許可のタブをチェックする。
まず、最初にチェックする箇所は、ブロックパブリックアクセスのページである。もしこれがすべてブロックにチェックが入っていれば、全て外しておく。今回は、チェックは入っていなかったため、このまま変更を保存した。
次にチェックする箇所は、バケットポリシーである。ここで、公開設定などを設定する。
早速ポリシー編集画面にアクセスし、以下のようなコードを追加した。
 バケット名の箇所には、作成したバケットであるir604の名前を入れた。
バケット名の箇所には、作成したバケットであるir604の名前を入れた。
すると、アクセス許可状態が公開に変化した。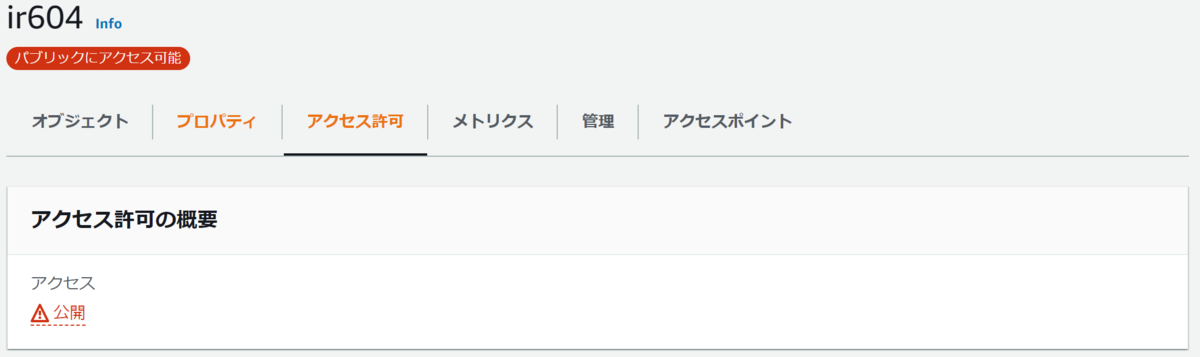
この状態で再度オブジェクトURLにアクセスした。すると、以下のような表示がされ、HTMLファイル及び、CSSファイルが公開されていることが確認できた。
バケット内のファイルのダウンロード
おまけとしてバケットにアップロードしたファイルをダウンロードする方法を試してみる。非常に単純で、
とすれば、バケットにアップロードしたファイルをすべてインストールすることができる。実際に実行してみると、以下のように表示された。これで、ダウンロードされたことが確認できた。
バケットの削除
やることは終わったため、バケットを削除する。こちらもChapter3と同じ方法でバケットを削除した。 こうして、HTMLファイルとCSSファイルをバケットで公開した。
こうして、HTMLファイルとCSSファイルをバケットで公開した。
Chapter13 boto3(後半)
今回は、boto3を用いたAWS APIの操作を行った。前半では、S3のオペレーションを行ったので、後半ではDynamoDBのオペレーションを行う。
デプロイ
まずは、デプロイを行う。/dojo/dynamodbディレクトリにて、デプロイの手順を行う。![]()
デプロイが終了すれば、TableName(本記事では※1とする。)が出力されたため、この文字列を記録。
Basic Read and Write
では、早速前半と同じ方法でjupyter notebookを開き、コードを入力してみる。
まずは、boto3、pprint、datetimeをインポートし、sessionにboto3のセッション、ddbにセッションのリソース(今回はdynamodb)を格納し、table_nameには、デプロイ時に出力された※1の内容を、tableにddbのテーブルを格納しておく。
これで準備は整ったので、アイテムを追加していく(In [5])。まずは、respを定義し、そこにput_item()メソッドでデータを書き込む。それぞれのデータを格納し終われば、get_item()とpprintで確認してみた。すると、入力したデータがすべて返ってきた。 これで、追加できたことが確認できた。
これで、追加できたことが確認できた。
次は、要素の内容の更新を行ってみる。update_item()メソッドで、prefectureの内容をAomoriと変化してみる。この際、prefecture属性を:val1とし、それを用いて更新を行っている。更新が終われば、["prefecture"]を呼び出し、確認してみる。すると、Tokyo→Aomoriに更新されていることが確認できた。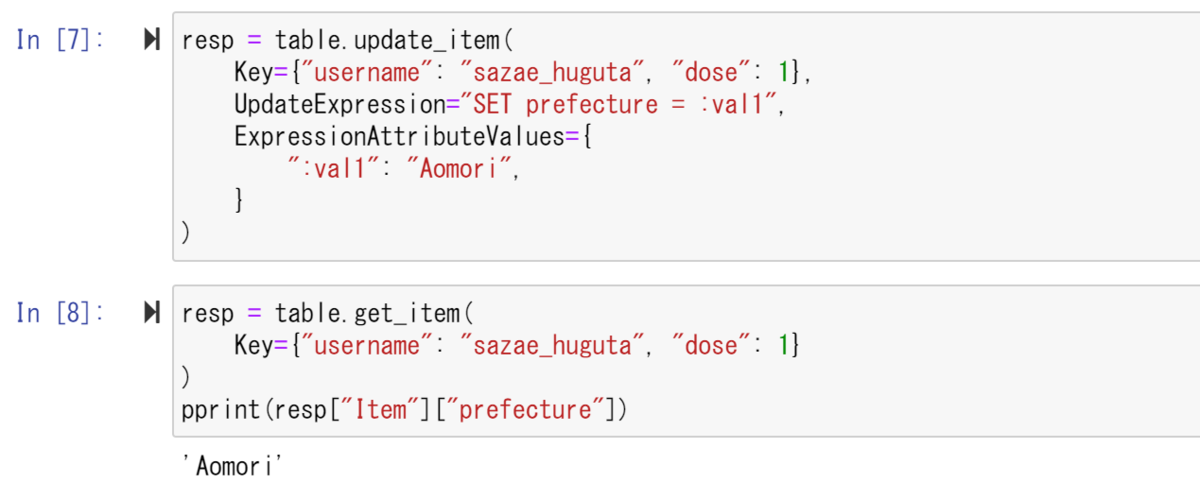
次に、statusの内容を更新してみる。前のprefectureのように、直接SET statusとはできないため、#at1という変数を定義し、そこにstatusを対応させている。 これで、resercedからcompletedに書き換えられた。
これで、resercedからcompletedに書き換えられた。
さて、最後にdelete_item()メソッドでデータを削除しておく。そして、再度get_item()で削除されていることを確認した。すると、以下のように表示された。 これで、削除されていることを確認できた。
これで、削除されていることを確認できた。
Query and Scan
次は、データベースに検索をかけ、データを取得してみる。まずは、jsonをインポートし、data.jsonを読み込み形式で開く。そして、batch_writer()メソッドを使い、jsonファイルをテーブルに書き込んでいく。

準備が整ったので、早速queryで検索をかけてみる。KeyConditionExpressionに検索内容を格納し、pprintで検索結果を表示させてみる。すると、二つの検索結果が帰ってきた。これは、ワクチンを一回目と二回目に打ったときのデータを返している。
そこで、一回目のデータのみを参照にするため、&で検索を更にかけてみた。doseの値が1の場合のみ出力するようにしてみる。すると、一回目のデータのみが表示された。
次は、Queryの実行を行う。ageの値が11、つまり、歳が11歳であるユーザーのみを出力するようにしてみる。すると、ageが11であるIsonoKatsuoというユーザーのワクチン接種データが確認できた。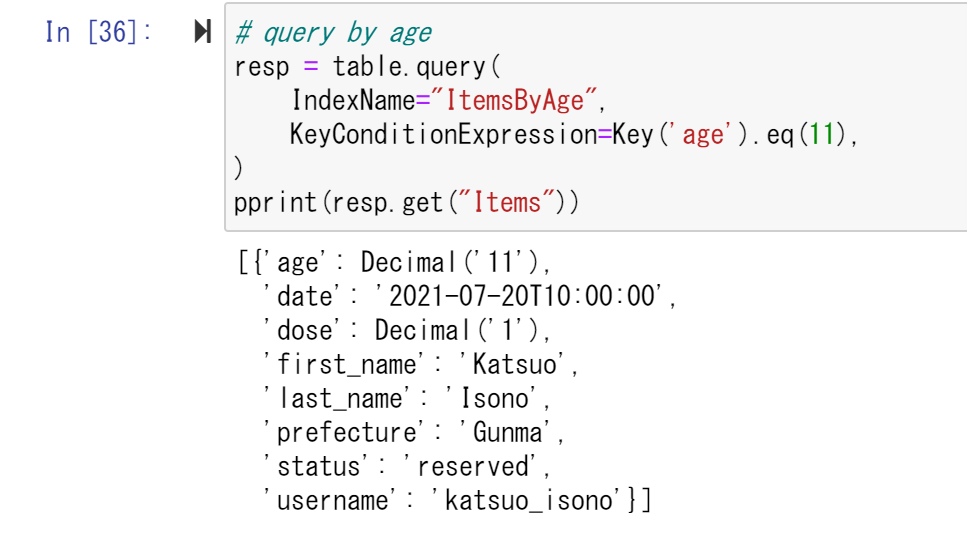
次は、prefectureを検索してみる。prefectureの値がTokyoの人のみを出力する。すると、HugutaTaraoとHugutaMasuoの二人の出力結果が得られた。
次に、条件を満たすアイテムの個数を検索してみた。scan()メソッドで検索をかけることができる。itemsにアイテムの個数を格納し、表示してみると、Number of items 8と出力された。
また、1MB以上の文字列を出力するためには、何度かScanを繰り返す必要があるため、whileで繰り返しScanを行う方法も実行した。こちらもNumber of items 8と出力された。
次は検索もかけてみる。27歳以下の人数を検索してみた。すると、以下のような出力結果が得られた。27歳以下の人物は3名いることがわかった。
次に、ある日時の予約一覧を見てみる。すると、IsonoNamiheiというユーザーが2021年7月25日に予約したことが確認できた。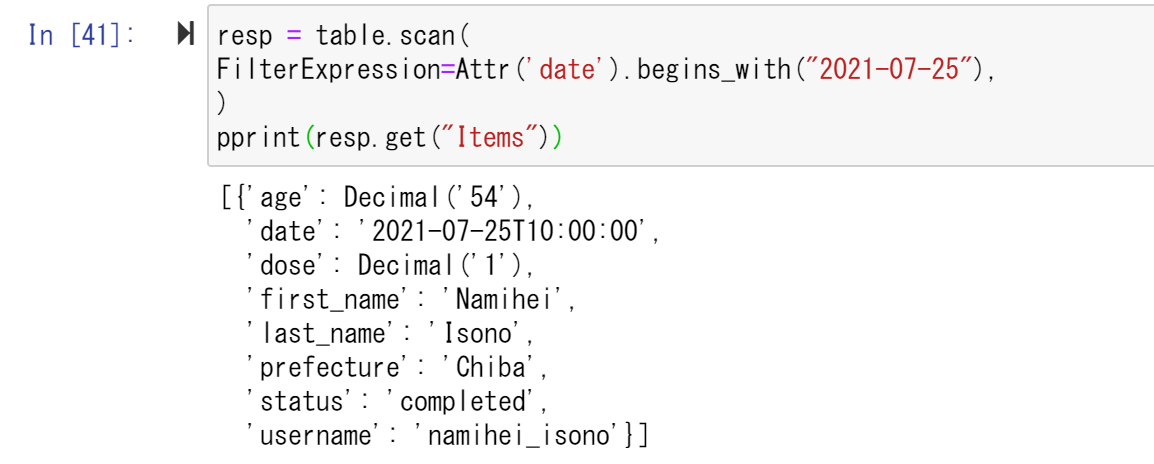
続いて、ある属性のみを抜き出してみる。ProjectionExpressionで、取り出したい属性を入力し、表示させると、この二つのみがこのように横に表示された。
Backing up a Table
続いては、バックアップを作成してみる。まずは、clientにdynamodbのクライアントを格納し、create_backupで、バックアップの作成を行う。
これで、バックアップの作成は完了したので、実際にバックアップの情報を取得し、確認した。
AWSからも確認してみる。DynamoDB/テーブルから、バックアップタブをクリックし、バックアップが一つあるのを確認した。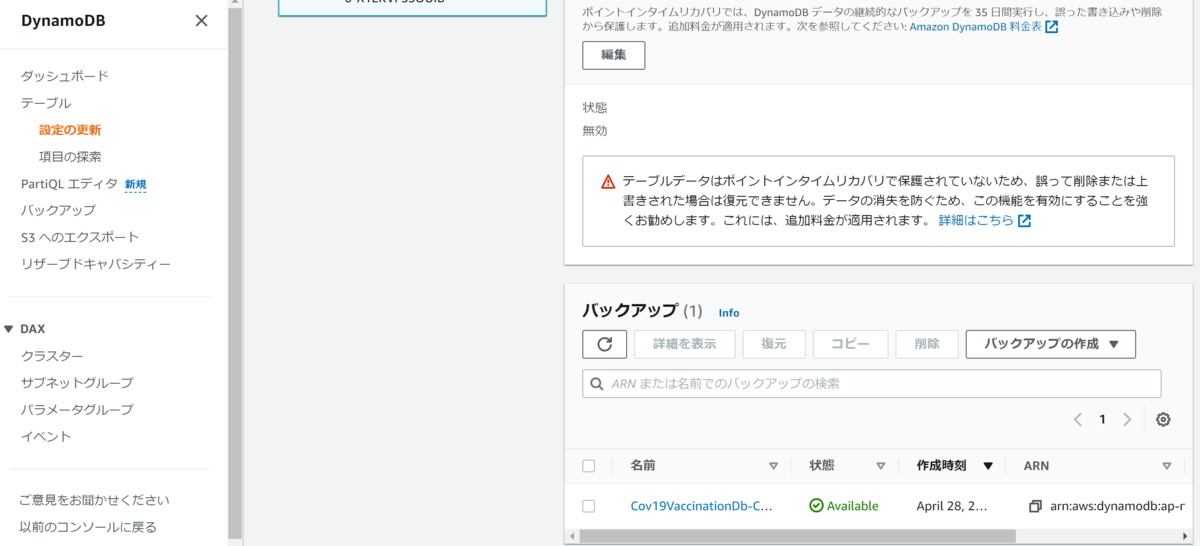
続いては、バックアップの復元を行ってみた。まず、アップデートの手順で情報を書き換える。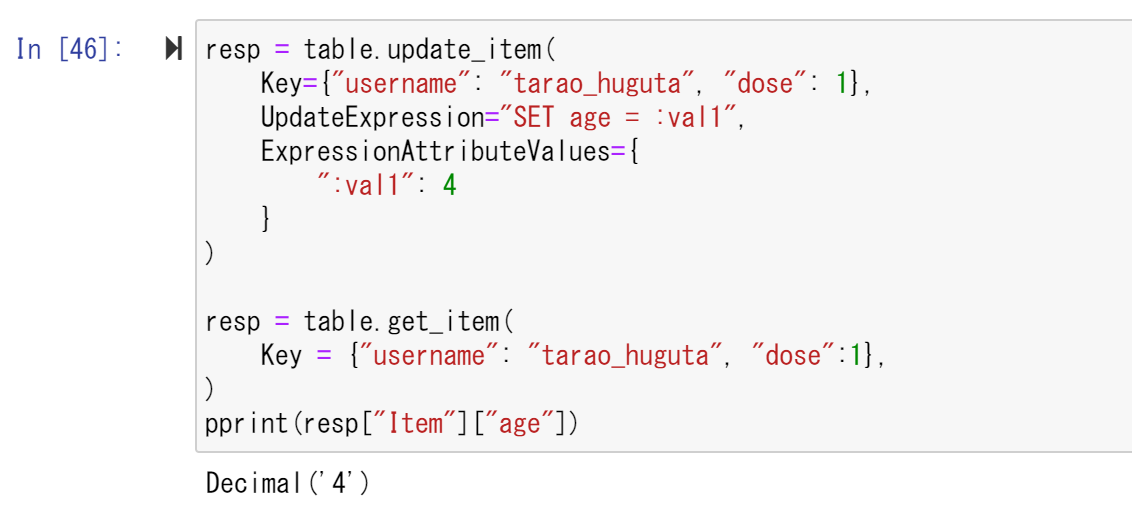
次に、バックアップの復元を行う。restore_table_from_backup関数を用いることで、バックアップの復元を行った。
ここで、復元したテーブルを見てみる。すると、最初はCREATINGと表示されたままだが、少し待ってから再度実行すると、ACTIVEに変化した。 早速、復元されたテーブルの情報を取得する。すると、Decimal('4')だったデータがDecimal('3')に復元されたことが確認できた。
早速、復元されたテーブルの情報を取得する。すると、Decimal('4')だったデータがDecimal('3')に復元されたことが確認できた。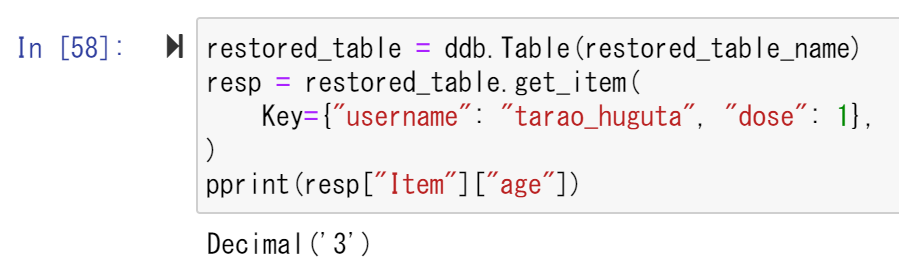
これで一通りやることは終わったので、テーブルとバックアップを削除した。 更に、スタックも削除しておいた。
更に、スタックも削除しておいた。
こうして、AWSをboto3で操作した。
Chapter13 boto3(前半)
今回は、boto3ライブラリを用いたAWS APIの操作を行った。前半と後半の二つに分け、前半では、S3のオペレーションを行う。
jupyterの起動
まずは、/dojo/s3ディレクトリでデプロイの手順を行い、デプロイを完了させる。
![]()
完了後、出力されるBucketName(本記事では※1とする)を記録し、jupyter notebookを起動する。
起動後、Ctrl+Cで終了の確認表示からjupyterのトークン(※2か※3)を確認できる。

そこで、※2か※3にブラウザでアクセスすると、以下のようなページが表示される。
これで、jupyterの準備は完了だ。
Basic IO
早速、NewからPython3のノートブックを開いた。
すると、jupyterのノートブックが開くため、以下のようなコードを打つ。boto3をインポートし、session、s3、bucket_name、bucketにそれぞれ、boto3のセッション、sessionのs3のリソース、バケット名(※1)、s3のバケットを格納し、tmp.txtファイルを書き込み形式で開き、Hello world!と書き込んでmyfile1.txtとmyfile2.txtファイルとしてアップロードしている。そして、最後にバケットのファイル一覧を取得している。
 すると、アップロードしたファイル名が二つ帰ってきている。アップロードが成功したことが確認できた。
すると、アップロードしたファイル名が二つ帰ってきている。アップロードが成功したことが確認できた。
次に、obj変数にmyfile1.txtのオブジェクトを取得し、ファイルのサイズと更新日時をそれぞれ表示してみる。すると、このような出力結果が得られた。
次は、ファイルをダウンロードしてみる。download_file("ファイル名")で、ファイル名を付けてダウンロードすることができた。
最後に、オブジェクトを削除する。delete()関数を呼び出すことで、削除できた。また、オブジェクトが削除されたかどうかを確認するため、オブジェクトの一覧を取得してみると、myfile1.txtが削除され、myfile2.txtだけが残っていることが確認できた。
In-memory data transfer
続いては、s3のオブジェクトをローカルマシンのメモリに直接ロードしてみる。まずは、pandasとioを新たにインポートし、DataFrameテーブルを作成し、df変数に格納。そして、格納したテーブルの中身を確認してみた。すると、以下のような表が表示された。
次は、csv形式で保存してみる。なお、この書き方には三通りほどあるのだが、今回は以下の方法で行う。
続いて、ローカルマシンのメモリーにロードしてみる。この書き方にも三通りやり方があるのだが、今回はこの書き方を用いる。
次は、画像データの読み書きを行う。まずは、PIL、numpy、matplotlibをそれぞれインポートする。その後、clownfish.jpgを開くimg変数を用意し、pyplotライブラリのimshow関数で画像を表示してみる。すると、このようなクマノミの画像が表示された。
続いては、その画像をバケットにアップロードしてみる。In[26]の書き方は、二通りあるのだが、今回はこの書き方を用いてアップロードする。そして、最後はclose関数でImageオブジェクトを閉じておく。
早速バケットにアップロードした画像をロードしてみる。これも二通りあるのだが、今回はこの書き方を用いて行った。すると、アップロードした画像と同じものが表示された。これで、直接ロードすることに成功し、なおかつ画像がアップロードされたことも確認できた。
PresignedURL
最後に、Presigned URLを利用してみた。まずは、PresignedURLを用いるのに必要なrequestsライブラリをインポートし、s3のクライアントを格納したclientオブジェクトを作成する。これで準備は整ったので、PresignedURLの発行を行う。resp変数に、generate_presigned_post関数で作成したPresignedURLを格納している。そして、Bucket変数で使用バケットを指定し、Key変数でオブジェクトのキーをupload.txtに指定し、ExpiresIn変数に失効時間を格納しており、今回は600秒後に失効することになっている。これを表示させると、 以上のように出力された。
以上のように出力された。
続いて、取得したPresignedURLを用いたアップロードを行ってみる。resp2オブジェクトにてアップロードを行う。すると、以下のように出力された。
Trueと返されたため、アップロードは成功したようだ。
さて、続いては、そのオブジェクトをresp3変数にてダウンロードしてみる。すると、以下のPresignedURLが発行された。ここにアクセスすると、ダウンロードが始まる。
ダウンロードされた、upload.txtを確認してみると、dummy.textの内容が格納されたupload.txtファイルを見ることができた。
直接開く以外にも、resp4でresp3を取得し、そのデータを参照することでダウンロードを確認した。すると、このように、Trueとファイルの中身が見ることができた。
さて、これでやることは終わったため、jupyterをCtrl+Cで終了し、スタックを終了した。
後半では、DynamoDBをboto3で動かそうと思う。
Chapter12 俳句アプリを動かす
今回は、サーバーレスクラウドを用いて、俳句アプリを実行してみる。
デプロイ
まずは、bashoutterディレクトリにて、デプロイの手順を行う。
無事デプロイが完了すれば、APIのページに行き、BashoutterApiが存在することを確認。
そして、そのAPI名をクリックすると、このような詳細を見ることができた。
続いては、BashoutterバケットをS3ページから見てみる。すると、bashoutter-…というバケットができていることがわかった。
次に、そのバケット名にアクセスし、中身を見てみる。すると、index.htmlファイルと、三つのディレクトリがあることが確認できる。
APIリクエスト
確認が終わったので、次はAPIリクエストの送信を行う。まずは、出力された文字列を何処かに記録しておく。本記事では、
- BashoutterApiEndpoint=※1
- BucketUrl=※2
として扱う。
まずは、exportでENDPOINT_URLという変数を作成しておき、その値に※1の内容を格納し、GETコマンドでENDPOINT_URL/haikuで、俳句の一覧を取得する。この状態で行うと、何も俳句が投稿されていないので、もちろん配列は空で帰ってくる。
次に、俳句を投稿してみる。POSTコマンドで、指定したurlに投稿を行う。例えば、このような俳句を投稿してみる。すると、このように表示された。
これで、俳句の投稿は成功したため、再び俳句の一覧を取得してみた。すると、以下のように表示された。 これで、無事投稿されたことが確認できた。
これで、無事投稿されたことが確認できた。
続いては、投稿した俳句にいいねを付けてみる。haiku/の次にitem_idを入れればアクセスできる。そして、PATCHコマンドでいいねを付けてみた。
実際に付けられたことを確認するため、再度俳句一覧を取得。 likesの値が0.0→1.0に変化したことが確認できた。
likesの値が0.0→1.0に変化したことが確認できた。
次に、投稿した俳句を削除してみる、DELETEコマンドで/haiku/item_idのアイテムを削除することができる。そして、俳句一覧を取得し、削除されたことを確認した。
最後に、大量にAPIリクエストを送るシミュレーションを行ってみる。client.pyファイルをENDPOINT_URLで300回実行してみると… 数秒立ったあとに、成功した。これで、大量のAPIリクエストに対応できることを確認できた。最後に、clear_databaseで、データベースを空にし、無駄なデータベースを削除しておく。
数秒立ったあとに、成功した。これで、大量のAPIリクエストに対応できることを確認できた。最後に、clear_databaseで、データベースを空にし、無駄なデータベースを削除しておく。
Bashoutter GUI
次はGUIを用いてみる。まずは、デプロイ時に出力された※2のURLにブラウザでアクセスしてみる。すると、このような俳句ページが表示された。

そして、API Endpoint URLに※1の値を入れてみる。その次に、REFRESHを押して見る。すると、APIリクエストを用いて俳句を投稿した状態ならば、以下のように一つ俳句が投稿されているページが表示された。
次は、ここから新しい俳句を投稿してみる。このように、俳句とユーザーネームを入力し、POSTで投稿してみた。
すると、この状態だと何も表示されていない状態なのだが、再びREFRESHを押すと投稿された俳句が表示される。
これで、やることは終わったため、スタックを終了する。
こうして、AWSで俳句アプリを動かした。
Chapter11 サーバーレスクラウド
本日は、サーバーレスクラウドをAWSを用いて動かしてみる。今回動かすサーバーレスクラウドは、以下の三つである。
- Lambda
- DynamoDB
- S3
また、それぞれのデプロイ用ディレクトリは、serverlessディレクトリに存在する。
Lambda
まずは、Lambdaを動かしてみる。lambdaディレクトリに移動し、Chapter7と同じ、SSH鍵無しのデプロイ手順を実行し、デプロイした。![]()
さて、デプロイが成功すれば、Lambdaのコンソールの関数ページに移動し、デプロイが成功していることを確認してみる。
次に、関数名をクリックし、コードソースを覗いてみた。 サーモン、ツナ、以下の三つからランダムで選び、それを表示するような内容となっている。
サーモン、ツナ、以下の三つからランダムで選び、それを表示するような内容となっている。
さて、次は動作確認を行ってみる。※1にデプロイ時に表示される水色で書かれたFunctionNameの文字列を記入し、invoke_one.pyファイルを実行してみる。すると、 このように、ランダムで選ばれた寿司ネタを出力されたことが確認できる。
このように、ランダムで選ばれた寿司ネタを出力されたことが確認できる。
さて、続いては、大量のタスクを実行してみる。invoke_many.pyファイルを実行し、タスク数を100に指定し、実行する。すると、少し時間を置き、Submitted 100 tasks to Lambda!と返される。
 これで、100個のタスクが実行されたはずだ。
これで、100個のタスクが実行されたはずだ。
それを確認するため、モニタリングタブを開き、グラフを見てみる。しばらくは何も表示されなかったが、数分待つと、グラフが表示された。 一通りやることは終わったので、これでLambdaは終了する。スタックの削除も忘れずに行った。
一通りやることは終わったので、これでLambdaは終了する。スタックの削除も忘れずに行った。
DynamoDB
続いては、DynamoDBを実行してみる。まずは、dynamodbディレクトリで今までと同じ手法でデプロイする。
そして、DynamoDBコンソールのテーブルページでデプロイができたことを確認。 できていることが確認できれば、項目の検索から、アイテムを見てみる。現地点では、何も書き込んでないため、何もない。
できていることが確認できれば、項目の検索から、アイテムを見てみる。現地点では、何も書き込んでないため、何もない。
さて、早速書き込んで見る。まずは、※2のTableNameを把握しておき、その文字列を語尾に書き込み、simple_write.pyファイルを実行してみる。
書き込みに成功したことが確認したあと、先程のアイテムの一覧(返された項目)を確認してみる。 項目が一つ増えてることが確認できた。これで、書き込みは成功だ。
項目が一つ増えてることが確認できた。これで、書き込みは成功だ。
さて、続いては、書き込んだアイテムを見てみる。simple_read.pyファイルを実行し、中身を見てみる。すると、以下のような結果が帰ってきた。
続いては、大量のデータを読み書きしてみる。
- python batch_rw.py ※2 write 1000
で、1000個のランダムデータを書き込んで見る。そこでアイテム一覧を見てみると、このような多くのデータが書き込まれていることが確認できた。

次に、search_under_age 2とUbuntu側で検索をかけてみる。すると、大きな遅延もなく、このような大量のデータが帰ってくる。 これでDynamoDBでやることは終わったので、こちらのスタックも終了する。
これでDynamoDBでやることは終わったので、こちらのスタックも終了する。
S3
さて、最後は、S3を動かしてみる。s3ディレクトリでデプロイの手順を行う。![]()
続いて、tmp.txtをアップロードしてみる。echoコマンドでtmp.txtを作成しておき、※3で表示されるBucketNameを加え、simple_s3.pyファイルのupload関数を実行し、アップロードする。
アップロードが終われば、次にアップロードされたファイルに対し、以下のようにa/b/tmp.txtを割り当てておく。
さて、これで一度、s3コンソールのバケットページにて、デプロイされたバケットを見てみる。tmp.txtと、a/ディレクトリがあることが確認できた。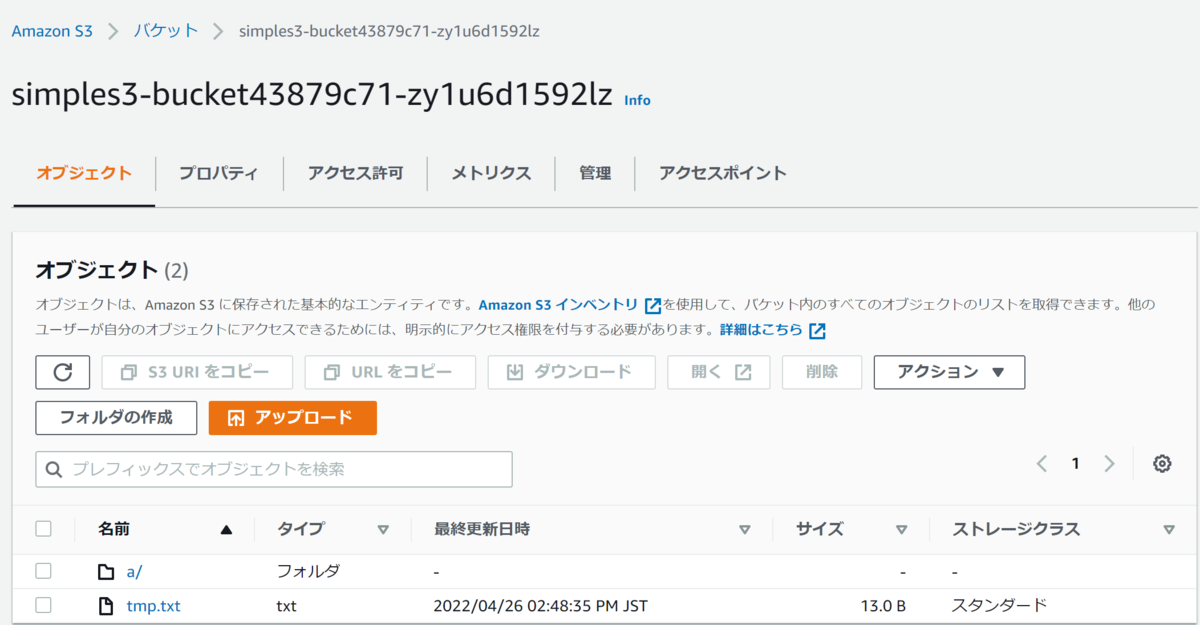
さて、続いてはtmp.txtファイルをダウンロードしてみる。uploadの箇所をdownloadにし、ダウンロードを実行した。 これで、S3でやることも終了したので、スタックを終了しておく。
これで、S3でやることも終了したので、スタックを終了しておく。
こうして、サーバーレスクラウドの実行を行った。
Chapter7 自動質問ボットをAWSで走らせてみる
本日は、アプリケーションをデプロイし、自動質問ボットを走らせる。
Dockerイメージをダウンロードし、実行。
まずは、そのためのDockerイメージをダウンロードする必要がある。以下のコマンドでDockerイメージをダウンロードした。 これで、自動質問ボットを用いることができるようになった。
これで、自動質問ボットを用いることができるようになった。
さて、早速動かしてみる。まずは、context変数に短英文を入れ、question変数に、質問を入れる。そして、
- docker run tomomano/qabot "短文(context)" "質問(question)" foo --no_save
で、質問を投げかけてみると… 1921と、答えを返した。答えに辿り着けているようだ。
1921と、答えを返した。答えに辿り着けているようだ。
他にも質問を投げかけてみると… 以下のように帰ってきた。
以下のように帰ってきた。
デプロイし、AWSでボットを走らせる
さて、ここからが本題だ。まずは、~/learn-aws-code/handson/qa-botディレクトリにて、
- python3 -m venv .env
- source .env/bin/activate
- pip install -r requirements.txt
- cdk deploy
で、デプロイする。
デプロイが完了したら、ECSのページにアクセスし、デプロイされたスタックを確認してみる。現在はスタックが一つも走っていないため、すべて0かデータなしである。
続いて、タスク定義からスタックを確認し、メモリの量などを確認した。
さて、次は質問を投げかけてみる。run_task.pyコードを実行し、"短文" "質問"の順番で投げかけた。すると、少し時間を置いたあとに、 以上のような結果が帰ってきた。Momotaroと、正解にたどり着いている。これで、自動質問ボットをAWSで走らせることは成功だ。
以上のような結果が帰ってきた。Momotaroと、正解にたどり着いている。これで、自動質問ボットをAWSで走らせることは成功だ。
大量の質問を投げかける
さて、これから質問を同時に大量に投げかけて、すべて処理することが可能なことを検証してみよう。まずは、
- python run_task.py ask_many
で、多くの質問タスクを投入してみる。
さて、これでECSのページに行き、多くのタスクが同時に実行されていることが確認できた。
次は、質問の回答を取り出してみた。すると、次々と回答が表示されてきた。 このように、複数の問題に対して処理できることがわかる。
このように、複数の問題に対して処理できることがわかる。
さて、一通り終われば、エントリーをすべて削除することにしよう。![]() 最後に、忘れずに
最後に、忘れずに
- cdk destroy
でスタックを削除する。
これで、AWSで自動質問ボットを動かした。
Chapter4 初めてのEC2インスタンスの起動
本日は、EC2のインスタンスの生成と、CDKにおけるハンズオンの方法について学んだ。
今回から初めてハンズオンを実行する。その際、ハンズオンのためのソースコードを事前にダウンロードしておく。
AWS CDKのインストールと設定
まずは、CDKをインストールする。インストールをする際は、Node.js(12.0以上推奨)が必須となる。まずは、以下のコマンドを実行し、CDKのインストールを行う。
- sudo npm install -g aws-cdk@1.100
本ハンズオンでは、1.100バージョンで動作するので、それに合わせてCDKのバージョンは1.100にした。
さて、続いてはbootstrapで初期設定を行う。
- cdk bootstrap aws://アカウント番号/リージョン名
と、ホームディレクトリ上で打ち込めば、初期設定は完了だ。

準備
ここからはハンズオンの準備を整える。まず、冒頭でダウンロードしたソースコードが格納されているディレクトリにアクセスし、handson/ec2-get-startedで、ディレクトリの移動を行う。
その後、pythonのvenv仮想環境内に依存ライブラリをインストールする。まず、
- python3 -m venv .env
で、env.という仮想環境を生成し、sourceコマンドで.env/bin/activateにアクセス。そうすると、(.env)と表示され、仮想環境にアクセスできたことがわかる。 さて、早速依存ライブラリを生成しよう。ec2-get-startedディレクトリ内に元々存在するrequirements.txtを読み込み、依存ライブラリをインストールする。
さて、早速依存ライブラリを生成しよう。ec2-get-startedディレクトリ内に元々存在するrequirements.txtを読み込み、依存ライブラリをインストールする。
これで、依存ライブラリのインストールは完了した。
次に、SSH鍵を生成する。まず、exportで、鍵の名前を格納する変数を用意する。そして、その変数を組み合わせ、AWS側と自分のPC側の両方にキーペアを作成する。
これでsshキーの作成は完了なのだが、最後に.sshディレクトリに移し、更にアクセス権限を400にしておく。
もし、アクセス権限の設定を行わないと、不正取得のリスクが大きい上に、そもそも下のような警告が出て、sshキーが無視される。
これで、準備は完了だ。
デプロイ&アクセス
さて、いよいよデプロイに移る。まずは、cdkのバージョンが1.100になってることを確認し、仮想環境内にアクセス。その状態で、キーネーム込でデプロイを行う。
デプロイには、少々時間が掛かるが、成功すると、以下のような結果が帰ってきた。
さて、インスタンスがAWSのEC2サービスにアクセスし、生成されているか確認してみる。
確認できたら、sshキーを用いてアクセスする。@以降は、EC2インスタンスのIPアドレスを入力。 成功すれば、上のような結果が返り、プロンプトの入力部分が[ec2-user@ip-……]となる。
成功すれば、上のような結果が返り、プロンプトの入力部分が[ec2-user@ip-……]となる。
EC2インスタンスを操作してみる
さて、EC2にアクセスしたので、少しデータを覗いてみよう。まずは、catで/proc/cpuinfoを覗いてみる。
続いては、topコマンドを実行し、実行中のプロセス、メモリの消費量を見る。
続いて、dfコマンドで、ストレージディスクについて調べる。 最後に、Python3をアップロードしてみる。まずは、yumをアップデートする必要があるため、sudoとupdateを用いてアップデート。
最後に、Python3をアップロードしてみる。まずは、yumをアップデートする必要があるため、sudoとupdateを用いてアップデート。
アップデートが完了すれば、python3.6をインスタンス内にインストールする。
Complete!と出れば、python3.6のインストールは完了である。
動作確認のため、python3と打ち、動作するかどうかを確認する。 >>>となれば、Python3.6のインストールは成功だ。確認できれば、Ctrl+Dで終了。
>>>となれば、Python3.6のインストールは成功だ。確認できれば、Ctrl+Dで終了。
EC2インスタンスを終了
さて、これで試したいことは終了したので、EC2からログアウトをする。exitと打てばログアウトできる。
最後にスタックが生成されているかを確認してみる。今回のハンズオンではMyFirstEc2というスタックを生成した。
そして、使い終わったインスタンスは削除。
ついでに、キーペアの削除もしておく。因みに、キーペアの削除は、これからもインスタンスを用いる場合は削除しなくても問題はない。
このように、初めてのEC2インスタンスの起動を行った。